

Our Agents
Each agent operates on a fundamental framework of observations, actions, and incentives that shape its behavior during training. The observations serve as the input, actions as the output, and incentives guide the learning process. Let's delve into how we structure these elements to develop our agents.
Observations: The Agent's Window to the World
Observations are the sensory inputs that the agent uses to understand its environment. These include:
Position Awareness: The agent knows its own position on the platform.
Directional Information: A normalized direction to the goal.
Distance Information: A normalized distance to the goal.
RayPerception3D Sensors: These are like lasers that shoot out and detect objects in the environment. In our setup, we have two types of RayPerception3D sensors:
Forward Sensor: Shoots straight out, giving the agent maximum reach to detect objects around it.
Downward Sensor: Pitched slightly downward to sense the ground and help prevent the agent from falling off the platform.
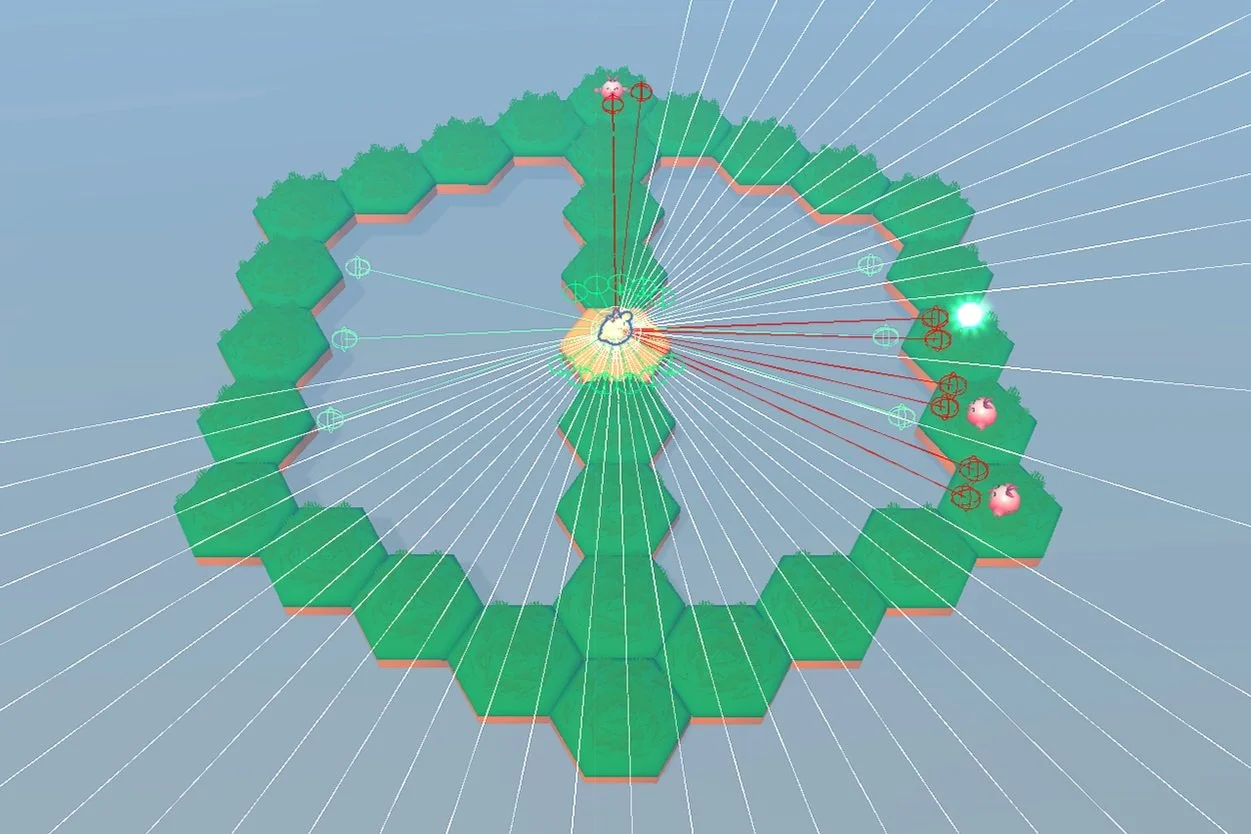
The observation space can be expanded with more sensors as challenges increase, which in-turn requires retraining the agent due to changes in the observation size (the input tensor size).
One key aspect to understand is how to calculate the observation size for each observation. Let's break it down with an example:
Position of the Agent: In a 3D space, this includes the X, Y, and Z coordinates, resulting in an observation size of 3 (one for each coordinate).
Distance to the Goal: We normalize this value from the agent's position to the goal's position, scaling it between 0 and 1, which makes its observation size 1.
Combining these, the agent’s position (size 3) and the distance to the goal (size 1) give us a cumulative observation size of 4.
The total observation size is crucial because it determines the number of input neurons in the agent's neural network. Each observation contributes to the input layer, and summing these sizes gives us the total number of input neurons the network will work with.
Actions: The Agent's Capabilities
Actions are the possible outputs an agent can make in the environment. For our goal-seeking agent, we’ve defined:
Move Forward/Backward: Controls the agent's movement along its current facing direction.
Rotate: Allows the agent to turn on the Y-axis.
These actions enable the agent to navigate the platform effectively. Like observations, changes in the action set will also necessitate retraining the agent from scratch.
Incentives: Guiding Behavior
Incentives are the rewards and penalties that guide the agent's behavior. This is where we get to shape how the agent learns and adapts. Here’s how we’ve set up incentives for our goal-seeking agent:
Penalty for Inaction: The agent receives a penalty for each step taken without finding the goal, creating a sense of urgency.
Reward for Progress: Moving closer to the goal yields a small reward, reinforcing the desired behavior.
Ultimate Reward: Reaching the goal grants the highest reward.
Unlike observations and actions, incentives can be modified on the fly without needing to restart the training process. This flexibility allows for dynamic adjustment of the agent's learning process.
In my opinion, adjusting the incentives is the most fun! Imagine training a dog to sit: the dog uses its senses and body similar to humans but initially, it will not understand the command. Without the magic word, T-R-E-A-T, getting it to do what you want will take a long time. But with a treat, the dog quickly learns to associate the command with the desired action to get that reward. Once the inputs and outputs are set, the incentives guide the agents' behavior. Even with identical inputs and outputs, agents with different incentives will learn different behaviors. Incentives are an art more than a science. Plus, we can change incentives even during training without having to retrain the agents from the start!